Every part - phoneme, word, sub-sentence, sentence, even the whole document could be represented as a vector. I found it really cool.
How to get this representation?
The most straightforward way is to build a word-documents matrix. This matrix will be sparse, so the next step should be a dimensionality reduction (e.g SVD).
The main problem here is an expensive computation (computation cost scales quadratically for n x m matrix O(m x n x n) when (n < m))
Another approach is to learn vector representation directly from the data. This algorithm (named word2vec) was suggested in 2013 by Mikolov. Actually, word2vec is a two algorithms: CBOW(continuous bag of words) and Skip-Gram. In CBOW you are predicting the word, based on words before and after. In Skip-Gram the task is opposite - context prediction based on words.
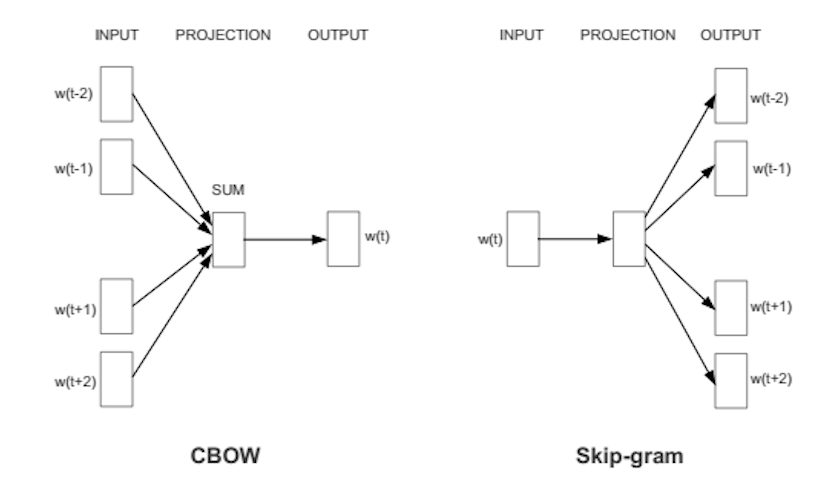
With this approach, you can very quickly learn words representation(e.g words representation for all words in English wiki (~80 GB unzipped texts) could be learnt in ~ 10 hours with office laptop).
You could directly measure the similarity between result vectors (and get a similarity between words context e.g. 'stock market' = 'thermometer', with similarity equal to 0.72). Also, you could use the vectors as building blocks for more complex neural nets.
This approach unlocks really cool new operations, like adding or subtraction word representations which look like adding or subtraction context of words.

Iraq - Violence = Jordan
President - Power = Prime Minister
Guys from Instagram applied this technique for obtaining meanings of emoji.
Example:

Interested in this topic? You can read more here:
Mikolov original paper:
http://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf
Instagram Engineering Blog:
http://instagram-engineering.tumblr.com/post/117889701472/emojineering-part-1-machine-learning-for-emoji
Cool examples (I used them above) http://byterot.blogspot.co.uk/2015/06/five-crazy-abstractions-my-deep-learning-word2doc-model-just-did-NLP-gensim.html
